![]()
AIDA64
Next up in our list of benchmarking tools is AIDA64, a suite that rivals Sandra for thoroughness.
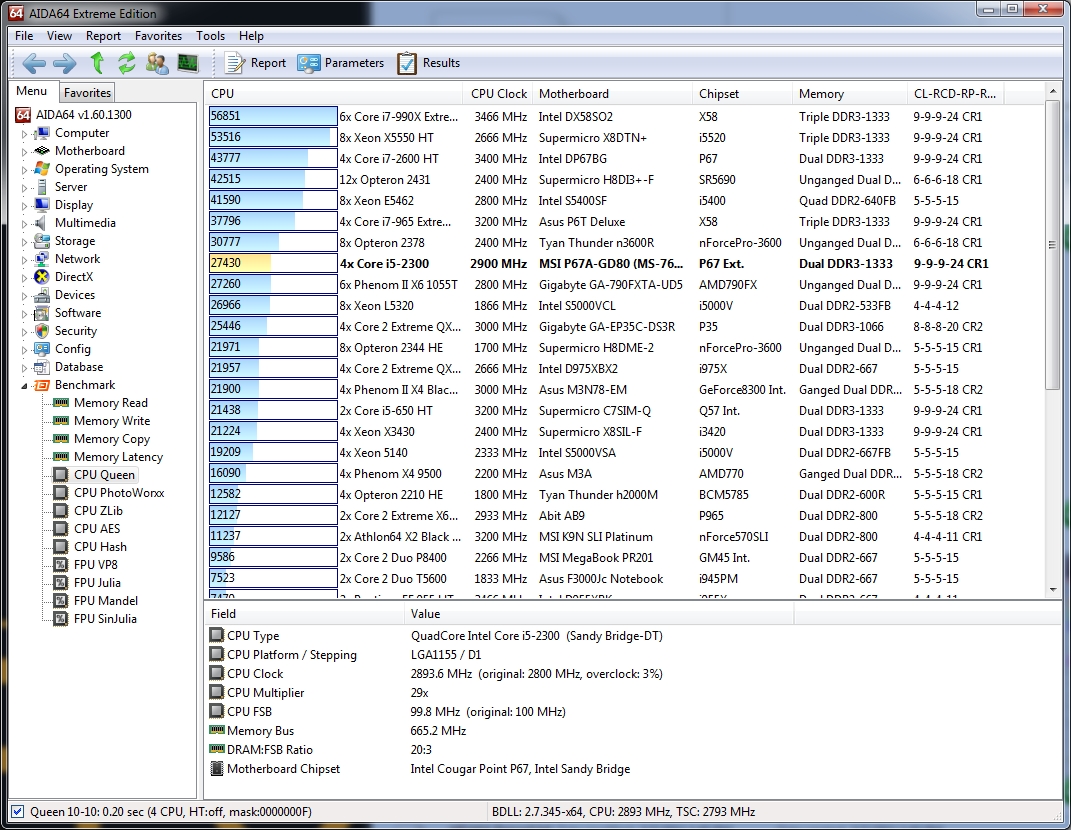
From the AIDA64 website, regarding the CPU Queen benchmark:
This simple integer benchmark focuses on the branch prediction capabilities and the misprediction penalties of the CPU. It finds the solutions for the classic “Queens problem” on a 10 by 10 sized chessboard. At the same clock speed theoretically the processor with the shorter pipeline and smaller misprediction penalties will attain higher benchmark scores…
Intel is clearly doing something right with the Sandy Bridge architecture; the i5 2300 scored higher than all the quad-core CPUs, save only those with HyperThreading—and thus more logical threads available.
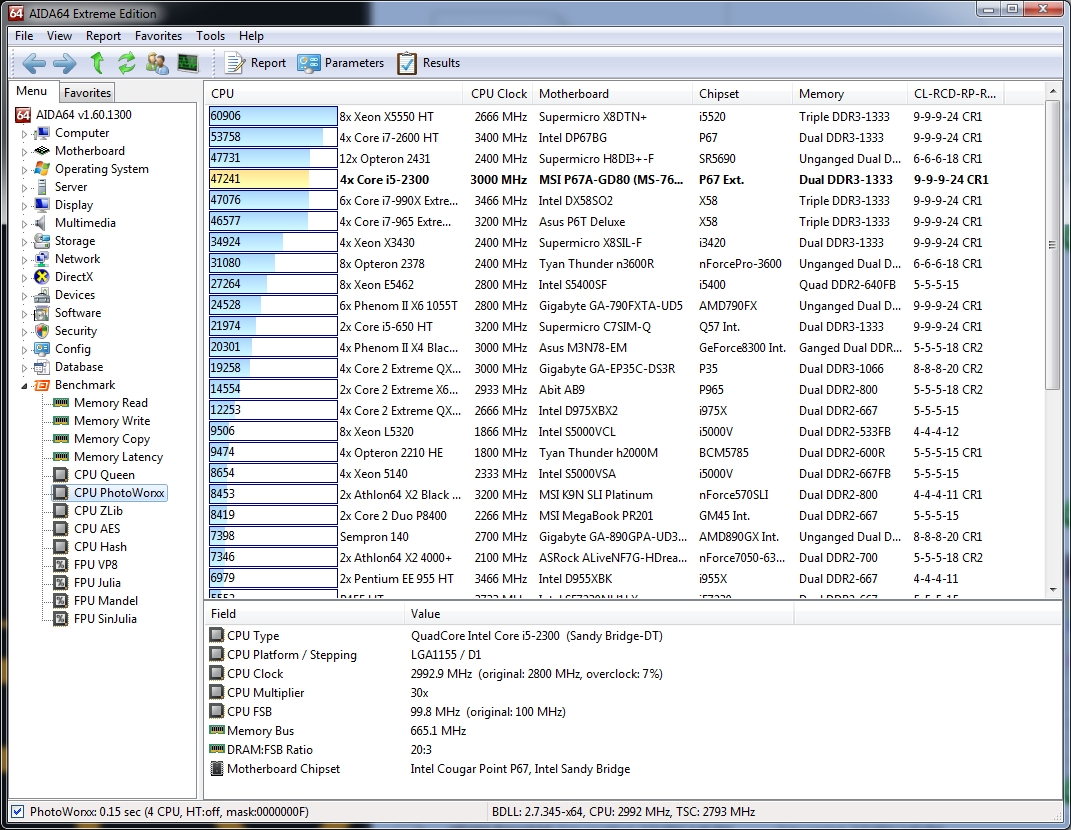
Regarding the CPU PhotoWorxx benchmark:
This benchmark performs different common tasks used during digital photo processing…
This benchmark stresses the integer arithmetic and multiplication execution units of the CPU and also the memory subsystem. Due to the fact that this test performs high memory read/write traffic, it cannot effectively scale in situations where more than 2 processing threads used. For example, on a 8-way Pentium III Xeon system the 8 processing threads will be “fighting” over the memory, creating a serious bottleneck that would lead to as low scores as a 2-way or 4-way similar processor based system could achieve. CPU PhotoWorxx test uses only the basic x86 instructions, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
Again the i5 2300 shows its muscle, beating out all but its own i7 sibling and a pair of server-grade CPUs.
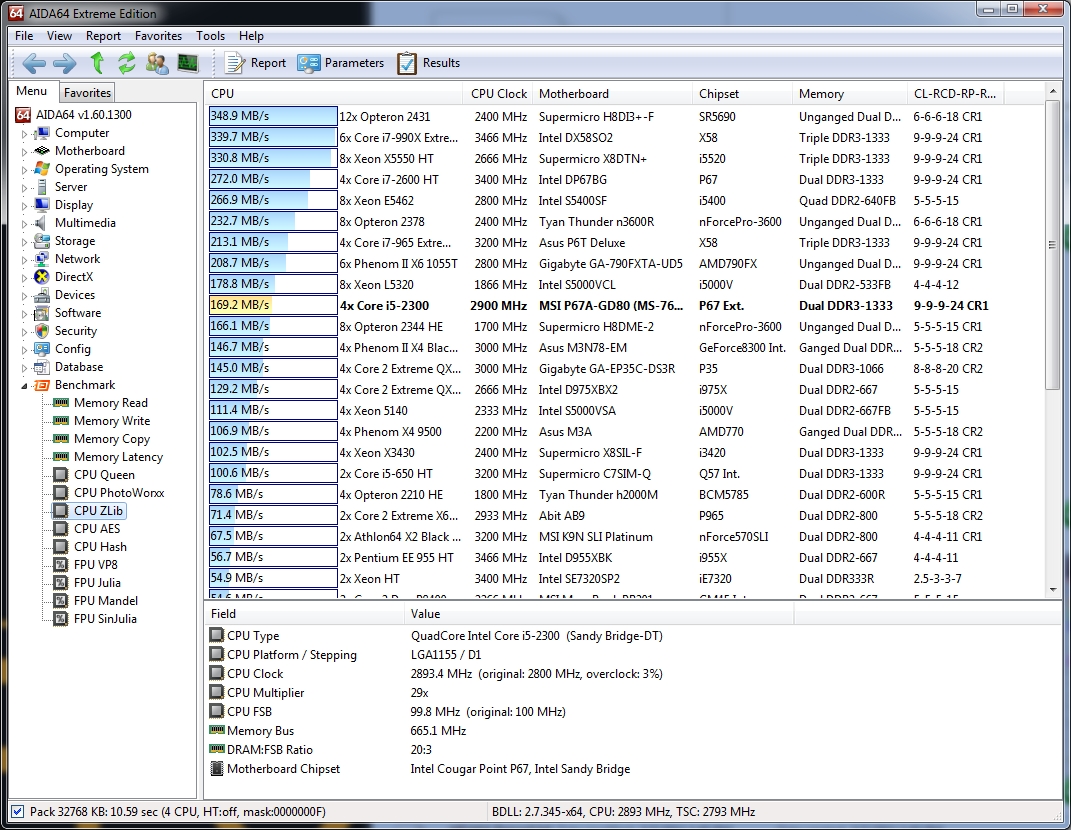
Regarding the CPU ZLib benchmark:
This integer benchmark measures combined CPU and memory subsystem performance through the public ZLib compression library. CPU ZLib test uses only the basic x86 instructions, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
Here the i5 2300’s performance is somewhat more modest, but again the pack ahead of it is filed with high-end enthusiast and server CPUs.
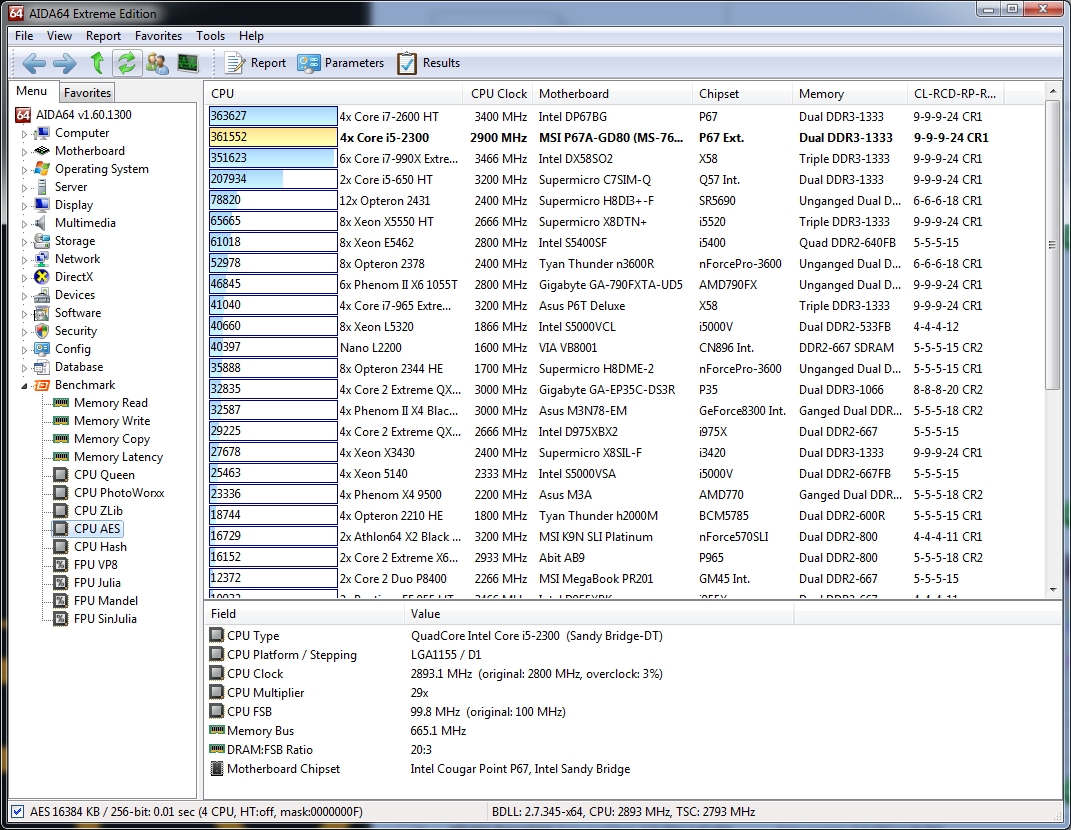
Regarding the CPU AES benchmark:
This benchmark measures CPU performance using AES (Advanced Encryption Standard) data encryption. In cryptography AES is a symmetric-key encryption standard. AES is used in several compression tools today, like 7z, RAR, WinZip, and also in disk encryption solutions like BitLocker, FileVault (Mac OS X), TrueCrypt.
CPU AES test uses only the basic x86 instructions, and it’s hardware accelerated on VIA PadLock Security Engine capable VIA C3, VIA C7 and VIA Nano processors; and on Intel AES-NI instruction set extension capable processors. The test is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
Here’s where the new AES instructions in the Sandy Bridge line show their worth: the i5 2300 beats out all but its i7 sibling in this test, and even squeezes into second ahead of a generally much beefier i7 from the Nehalem line.
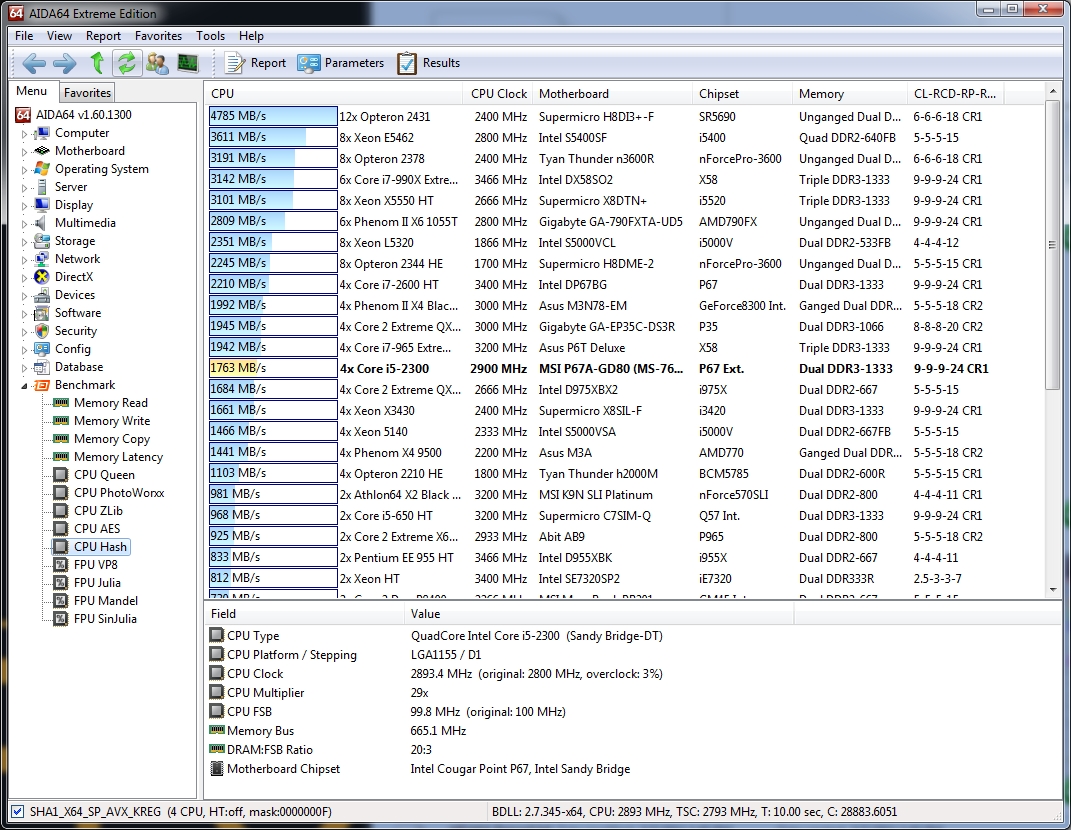
Regarding the CPU Hash benchmark:
This benchmark measures CPU performance using the SHA1 hashing algorithm defined in the Federal Information Processing Standards Publication 180-3. The code behind this benchmark method is written in Assembly, and it is optimized for every popular AMD, Intel and VIA processor core variants by utilizing the appropriate MMX, MMX+/SSE, SSE2, SSSE3, or AVX instruction set extension. CPU Hash benchmark is hardware accelerated on VIA PadLock Security Engine capable VIA C7 and VIA Nano processors.
Here the i5 2300 starts to fall behind a bit, mostly due to raw clock speed and number of available threads. Even so, the results are nothing to sneeze at, with our test system coming in the top 20.
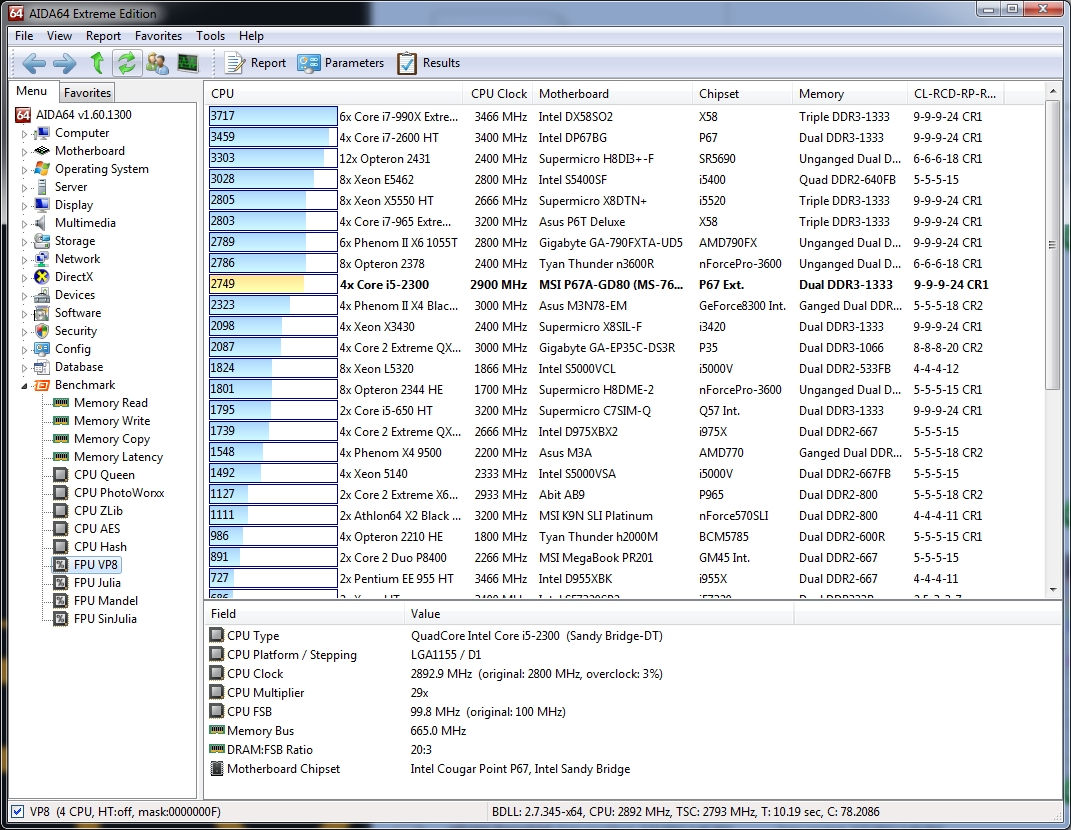
Regarding the FPU VP8 benchmark:
This benchmark measures video compression performance using the Google VP8 (WebM) video codec Version 0.9.5 (http://www.webmproject.org). FPU VP8 test encodes 1280×720 pixel (“HD ready”) resolution video frames in 1-pass mode at 8192 kbps bitrate with best quality settings. The content of the frames are generated by the FPU Julia fractal module. The code behind this benchmark method utilizes the appropriate MMX, SSE2 or SSSE3 instruction set extension, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
I’m starting to see a pattern here: our test system is smoking everything else with 4 threads, and staying competitive with the 6- and 8-thread systems.
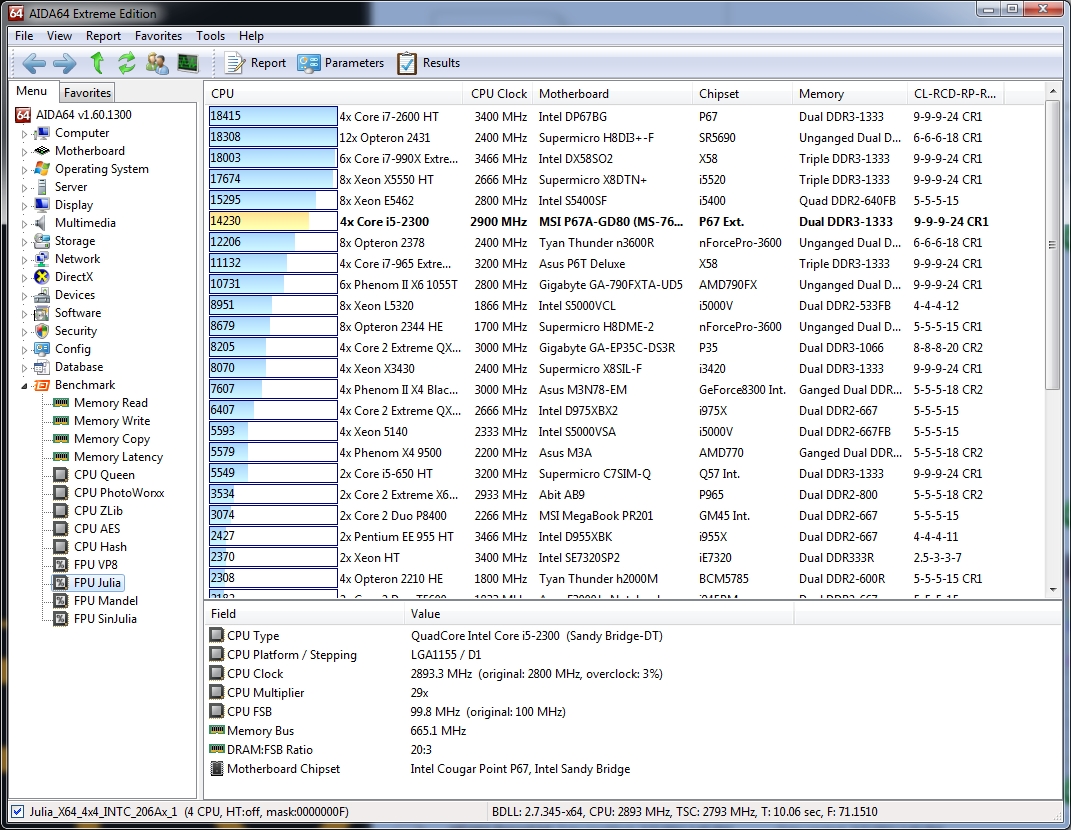
Regarding the FPU Julia benchmark:
This benchmark measures the single precision (also known as 32-bit) floating-point performance through the computation of several frames of the popular “Julia” fractal. The code behind this benchmark method is written in Assembly, and it is extremely optimized for every popular AMD, Intel and VIA processor core variants by utilizing the appropriate MMX, MMX+/SSE, SSE2, SSSE3, or AVX instruction set extension. FPU Julia test is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
Clearly the beefy vector execution units on the i5 2300 are serving us well, with our test system smoking every desktop processor on the market save only a handful of Intel’s finest.
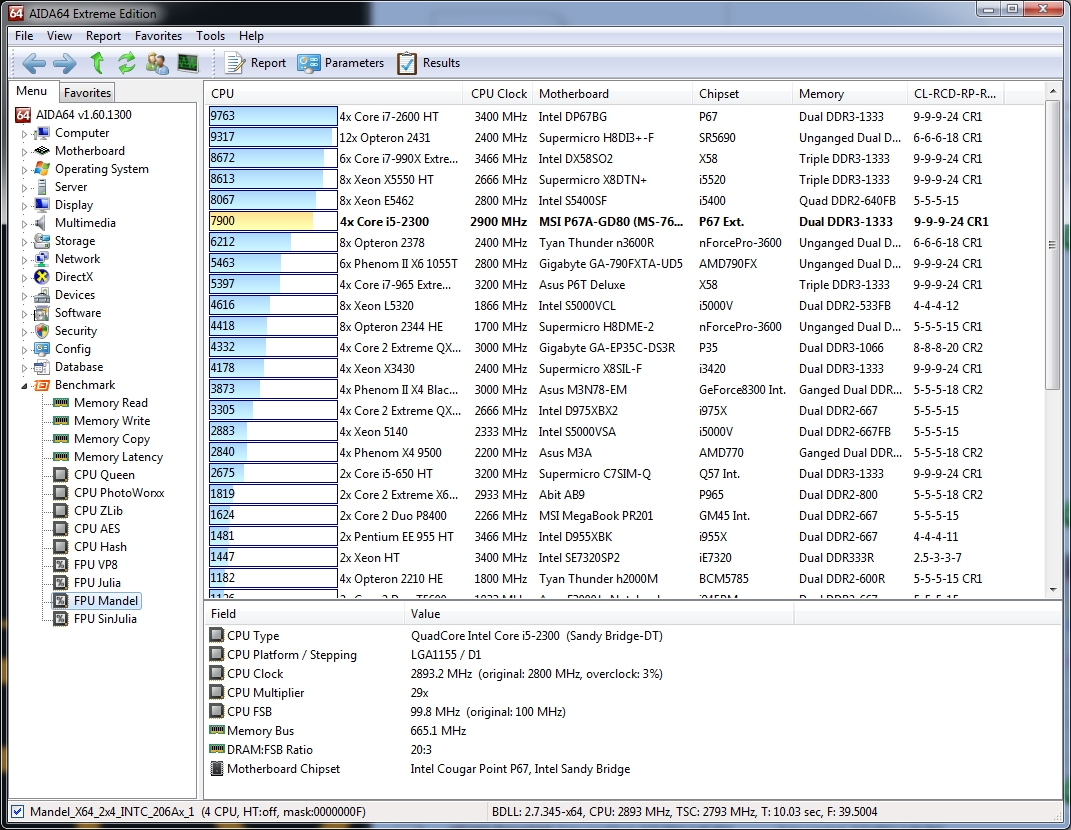
Regarding the FPU Mandel benchmark:
This benchmark measures the double precision (also known as 64-bit) floating-point performance through the computation of several frames of the popular “Mandelbrot” fractal. The code behind this benchmark method is written in Assembly, and it is extremely optimized for every popular AMD, Intel and VIA processor core variants by utilizing the appropriate MMX, MMX+/SSE, SSE2, SSSE3, or AVX instruction set extension. FPU Mandel test is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
I’m running out of creative ways to say “beats almost every desktop CPU on the market”, but that’s a pretty good problem to have. Here the poly-threaded beasts don’t even have much of a lead.
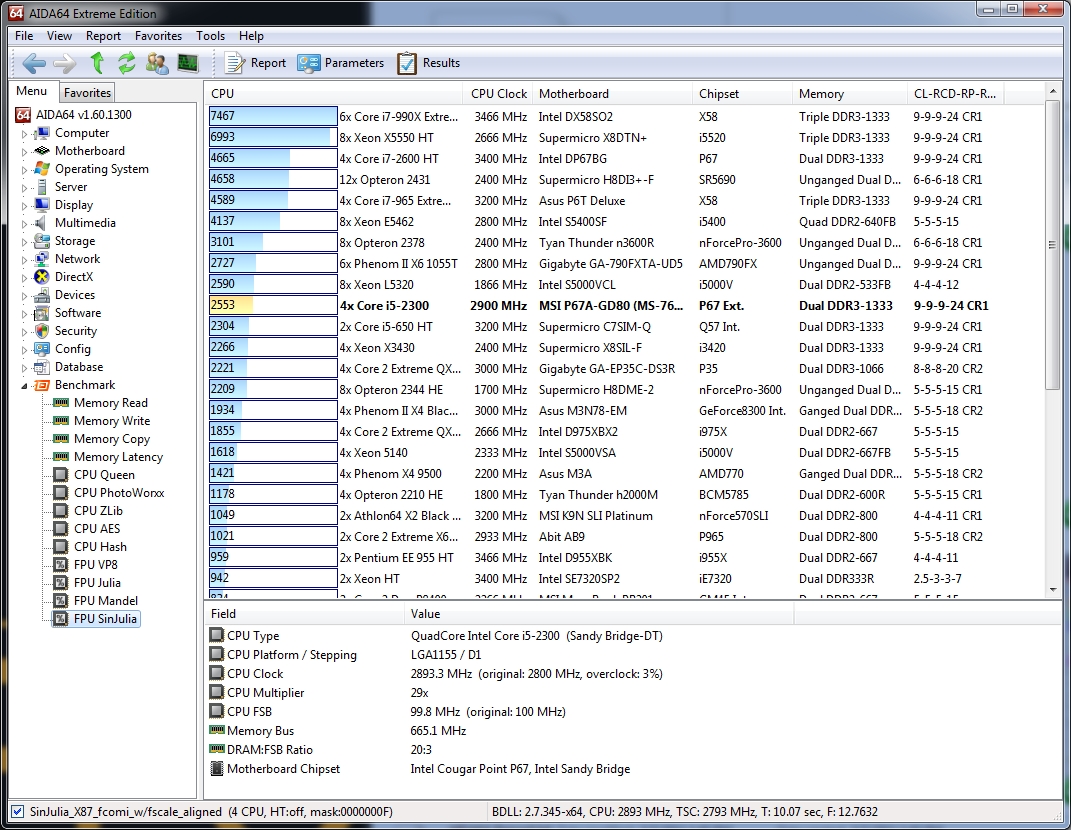
And last but not least, we have the FPU SinJulia benchmark:
This benchmark measures the extended precision (also known as 80-bit) floating-point performance through the computation of a single frame of a modified “Julia” fractal. The code behind this benchmark method is written in Assembly, and it is extremely optimized for every popular AMD, Intel and VIA processor core variants by utilizing trigonometric and exponential x87 instructions. FPU SinJulia is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
Here’s where both clock speed and number of threads makes a difference; our test system, while still quite blisteringly fast, falls behind the rigs with more and faster logical cores.
 |
 |
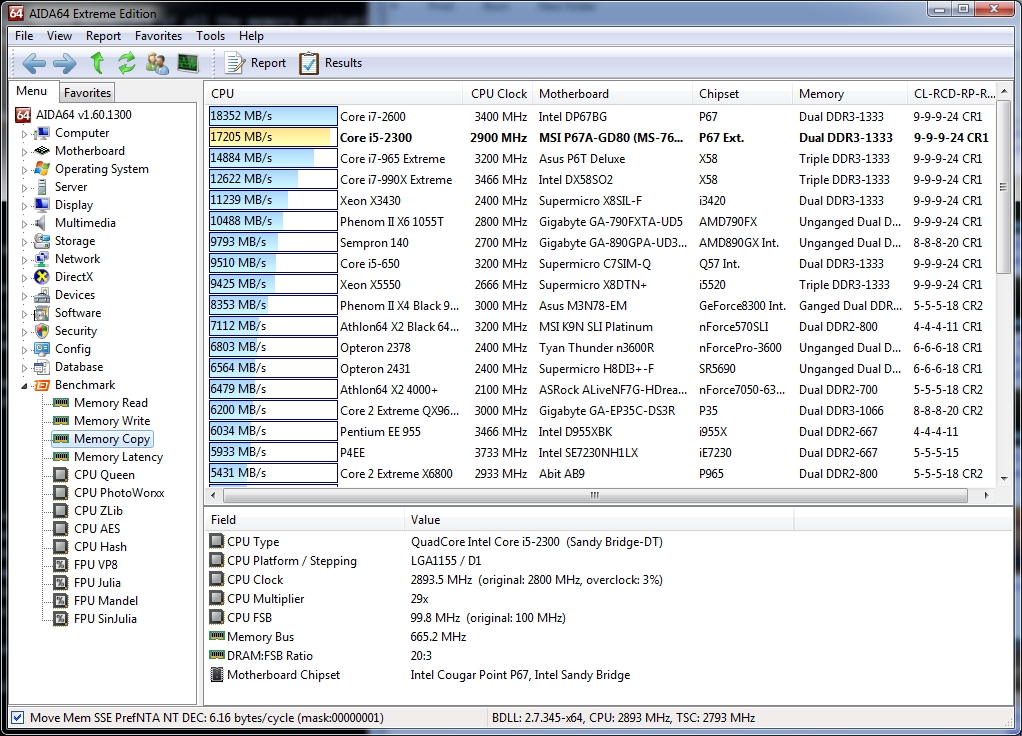 |
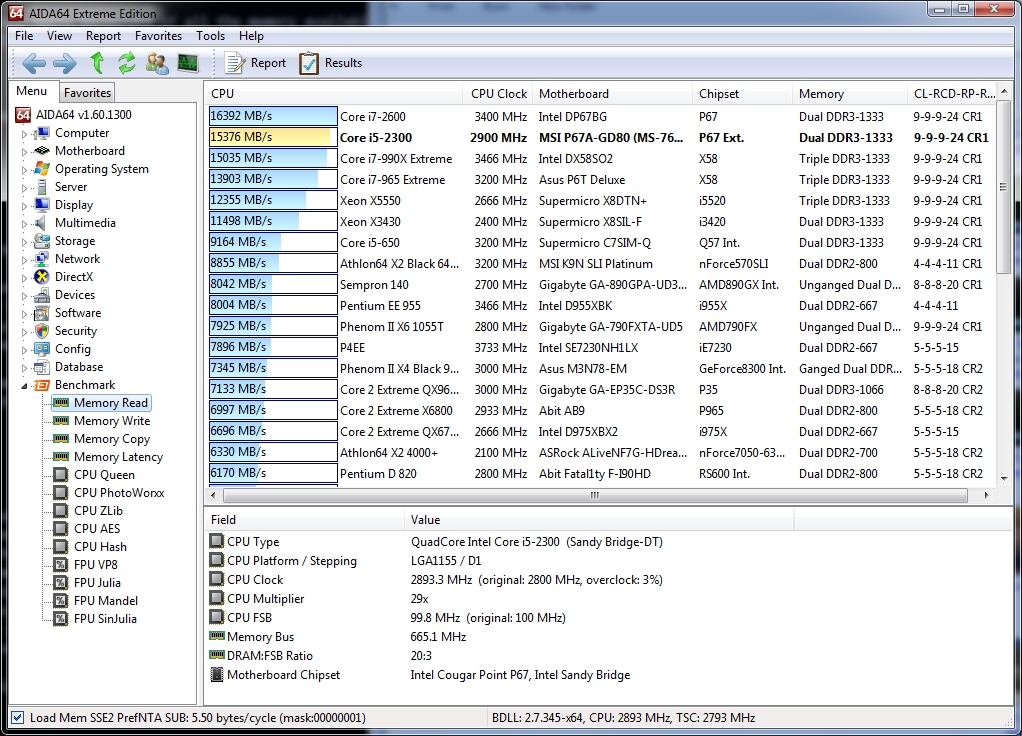
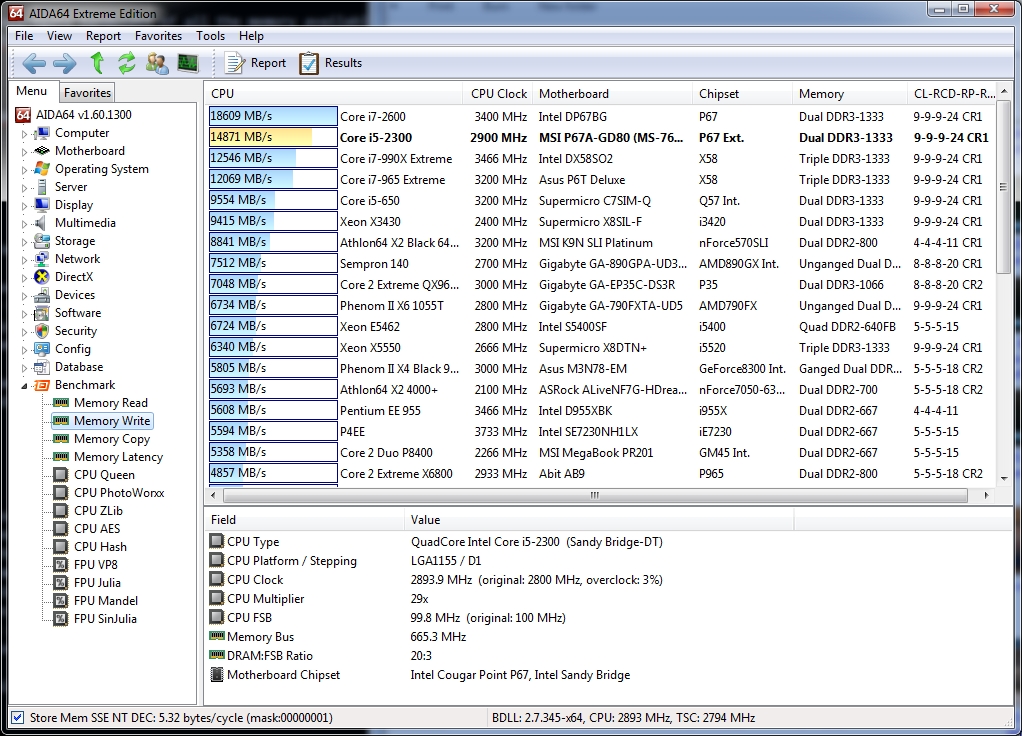
Now we’re on to the memory benchmarks; we’ll tackle Memory Read, Write and Copy as a trio:
Memory bandwidth benchmarks (Memory Read, Memory Write, Memory Copy) measure the maximum achievable memory data transfer bandwidth. The code behind these benchmark methods are written in Assembly and they are extremely optimized for every popular AMD and Intel processor core variants by utilizing the appropriate x86, MMX, 3DNow!, SSE, SSE2 or SSE4.1 instruction set extension.
Eerily, the rankings on all three benchmarks are identical, with the i7 2600 and i5 2300 taking the top two spots. The Sandy Bridge architecture is showing some blistering throughput here.
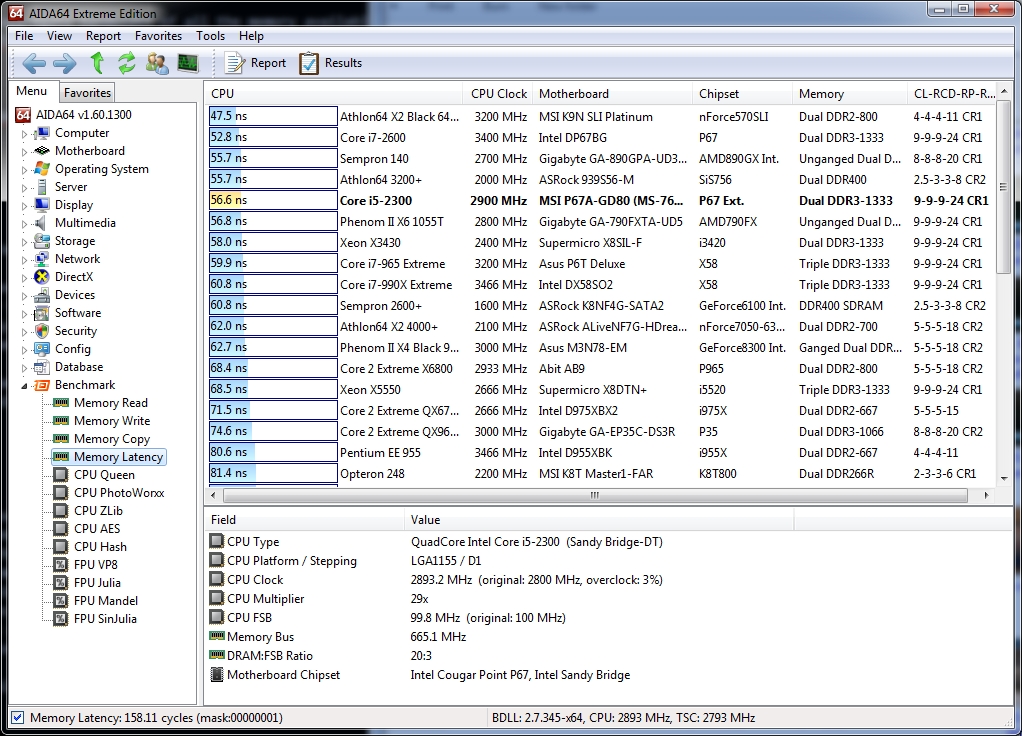
Last for this suite, we’ll take on the Memory Latency test:
The Memory Latency benchmark measures the typical delay when the CPU reads data from system memory. Memory latency time means the penalty measured from the issuing of the read command until the data arrives to the integer registers of the CPU.
Here is where the P67 chipset shows its strength: the memory latency is solidly in the top five.

[…] MSI P67A-GD80 Motherboard @ TechwareLabs […]
[…] TechwareLabs Evocarlos @ MSI forums *expect to see more reviews in the coming […]
[…] MotherboardsMSI P67A-GD80 @ TechwareLabs […]
[…] MSI P67A-GD80 Motherboard | TechwareLabs […]
[…] MotherboardsMSI P67A-GD80 @ TechwareLabs […]
[…] MSI P67A-GD80 Motherboard @ Techwarelabs […]
[…] by storm. MSI's swinging for the bleachers here, let's see if they hit a Grand Slam or a foul ball.http://www.techwarelabs.com/msi-p67a-gd80-motherboard/DiggLeave a Reply Click here to cancel reply. Name (required) Mail (will not be published) […]
[…] P67A-GD80 Motherboard – TechwareLabs […]